
Segformer
Segformer
结构图
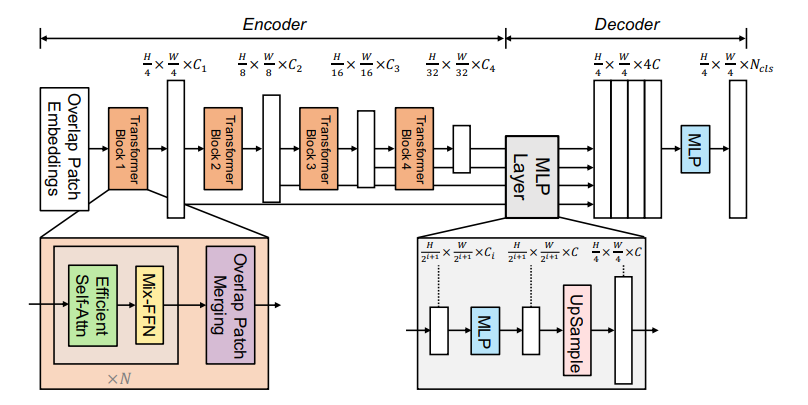
数据流
总览:
encoder: 以backbone mitb0为例,512x512x3的图像输入overlap patch embedding之后为128x128x64,然后进入transformer block,高宽通道数不变得到结果对应上图$\frac H4 \times \frac W4 \times C_1$,作为stage2的输入,以此类推得到$\frac H8 \times \frac W8 \times C_2$ , $C_3$…
decoder: 得到四个特征图(对应图中的channel数$C_1C_2C_3C_4$),每个特征图经过一个mlp层通道数统一为$C$ ,然后经过上采样高宽同一为$\frac H4 \times \frac W4$后进行concat,再经过一个mlp把通道数变为分割类别数。
细节
Tranformer Block的变化:
efficient self-attn基于self-attn的改进:对于$(N,C)$,reshape为$(\frac NR,C \times R)$然后$Linear(C\times R ,C)$再去做atttention,这样做的好处是complexity从$O(N^2)$降到$O(\frac {N^2}R)$
Mix-FFN基于FFN的改进:去掉位置编码(PE),原因是PE的分辨率是固定的,对于测试分辨率和训练分辨率不一致的情况下,通过插值会影响准确率,而且认为对于分割任务PE并不重要,认为3X3的卷积足以提供位置信息。新引入的Mix-FFN为
$X_{out}=MLP(GELU(Conv_{3\times3}(MLP(X_{in}))))+X_{in}$