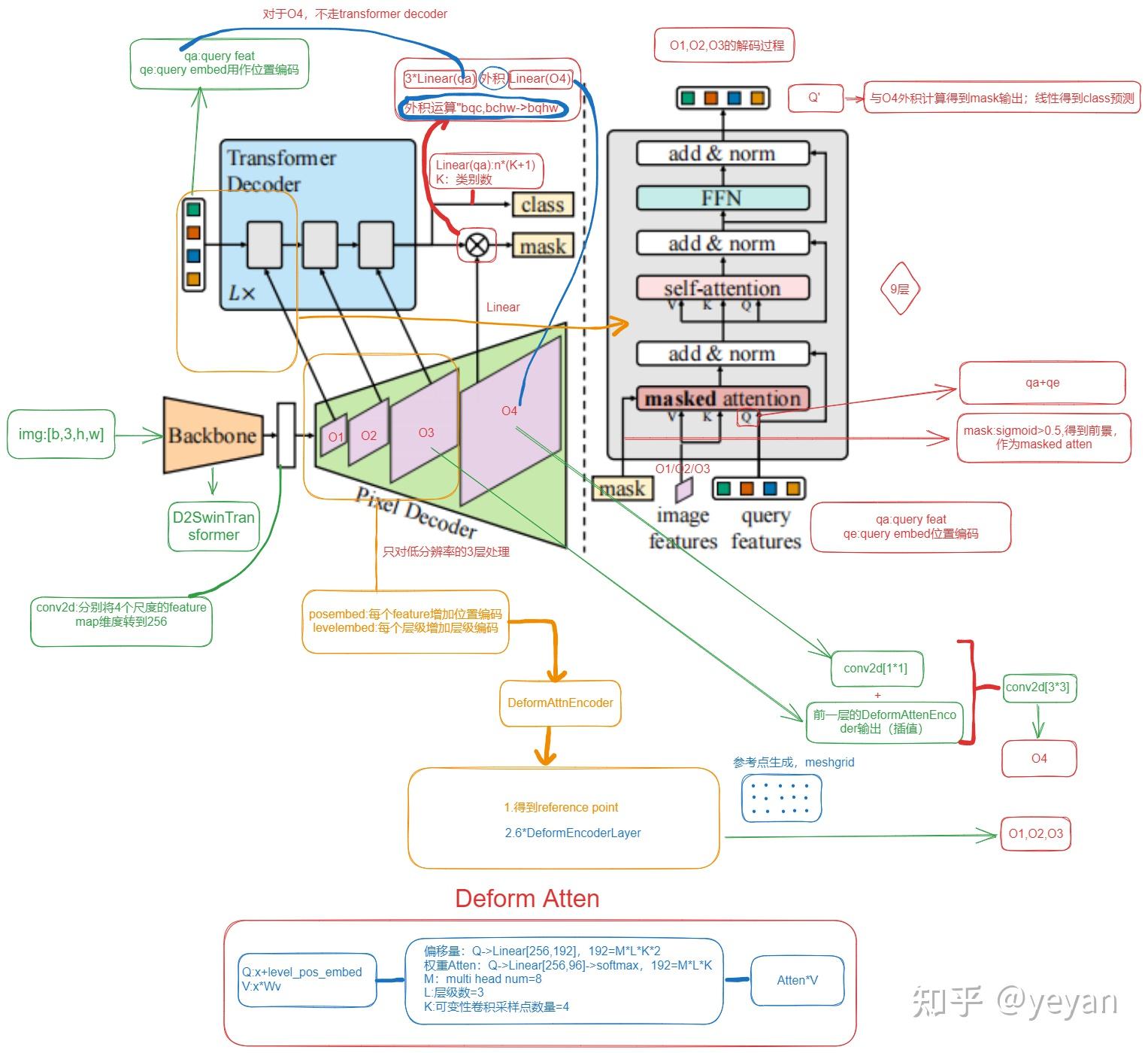
- 输入尺寸:输入图像的尺寸是 $B×3×512×512$,其中 $B$ 是批量大小,3是颜色通道数,512是图像的高度和宽度。
- 特征提取:通过主干网络(Backbone)提取特征 $F$,这些特征图的维度通常是 $B×C×H′×W′$,其中 $C$ 是特征通道数,$H′$ 和 $W′$ 是特征图的空间维度。
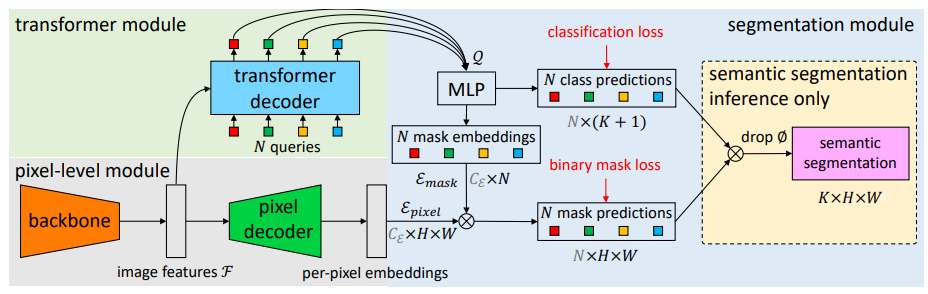
- 像素解码器:像素解码器(Pixel Decoder)上采样特征图 $F$ 以生成不同分辨率的特征图 $F1,F2,F3,F4$。这些特征图用于Transformer Decoder中的交叉注意力(Cross-Attention)。
- Object Queries:Object Queries是可学习的嵌入向量,维度为 $B×N×embeddim$,其中 $N$ 是Query的数量,$embeddim$ 是嵌入维度。
- Transformer Decoder:在Transformer Decoder中,Object Queries作为查询(Q),而特征图 $F1,F2,F3$分别作为不同Transformer Decoder层中的键(K)和值(V)。这里需要注意的是,每个Transformer Decoder层可能使用不同分辨率的特征图,而不是所有层都使用 $F1,F2,F3$。
- 输出分支:Transformer Decoder的输出通常有两个分支,一个是分类向量 $B×N×num_classes$,另一个是掩码向量 $B×N×H′×W′$。这里的 $H′$ 和 $W′$ 应该与输入图像的分辨率相同或经过一定的下采样。
- 掩码乘积:特征图 $F4$可能用于与预测的掩码进行乘积,以生成最终的像素级特征表示。这个步骤有助于将掩码信息整合到特征图中,以便进行类别预测。
- 损失计算:分类损失和掩码损失分别从两个分支计算。分类损失通过比较每个Query的预测类别与真实类别来计算,而掩码损失通过比较预测掩码与真实掩码来计算。
